Girl Genius for Wednesday, July 16, 2025
Jul. 16th, 2025 04:00 amThe Girl Genius comic for Wednesday, July 16, 2025 has been posted.
In the Busy Beaver game we ask: what is the longest that a Turing machine program of N states and K colors can run before halting when started on the blank tape? Answering this question requires enumerating every such program and checking whether or not it halts. But there is a big problem: there are just too many to check. The number of programs grows multiple-exponentially with N and K, O(nknk). Yikes!
Brady’s algorithm is an enumeration technique that allays this situation somewhat. It is based on two observations. First, we know that the Turing machine programs will be run from the blank tape. This constrains the possible execution paths. An arbitary program may have instructions that are simply unreachable in these circumstances, and there is no need to consider such programs. Second, some programs are isomorphic duplicates of each other, differing only in having their states or colors rearranged. There is no need to consider these duplicates, and only one program from an isomorphic group will need to be considered.
So the algorithm goes like this. Start on the blank tape with a program whose only instruction is A0:1RB. Then run it until an undefined instruction is reached. Then enumerate all possible instructions, pursuant to the following restriction: a new state can only be used if all prior states have been used. For example, state D cannot be used until state C has been used, and state E cannot be used until state D has been used, etc. And likewise for colors. Then for each such instruction, create an extension of the program with that instruction inserted and recursively continue the procedure. This ensures that only programs with actually reachable and meaningfully distinct instructions are generated.
It’s a cool algorithm, and a dramatic improvement over naive program generation. But even still, there are an awful lot of programs to generate, and running the algorithm can take quite a long time. So it is very important to pay attention to fine implementation details and take advantage of low-level performance hacks wherever possible. Small gains add up!
For some context, we will consider a real-world, used-in-anger, known-good implementation of Brady’s algorithm written by Shawn and Terry Ligocki and offer a few suggestions to make it faster. These are the sorts of changes that apply generically; basically any implementation of the algorithm will deal with these same issues. (Hopefully it goes without saying, but nothing here should be construed as negative or critical. This is fine code that has already proved its worth.)
There is some set-up to get the whole apparatus going. We will ignore all of that and jump straight into the action:
class TM_Enum:
def set_trans(self, *, state_in, symbol_in, symbol_out, dir_out, state_out): ...
def enum_children(self, state_in, symbol_in):
max_state = 0
max_symbol = 0
num_def_trans = 0
for state in range(self.tm.num_states):
for symbol in range(self.tm.num_symbols):
trans = self.tm.get_trans_object(state_in=state, symbol_in=symbol)
if trans.condition != Turing_Machine.UNDEFINED:
num_def_trans += 1
max_state = max(max_state, trans.state_out)
max_symbol = max(max_symbol, trans.symbol_out)
num_states = min(self.tm.num_states, max_state + 2)
num_symbols = min(self.tm.num_symbols, max_symbol + 2)
if num_def_trans < self.max_transitions:
for state_out in range(num_states):
for symbol_out in range(num_symbols):
for dir_out in range(2):
new_tm_enum = copy.deepcopy(self)
new_tm_enum.set_trans(
state_in=state_in,
symbol_in=symbol_in,
symbol_out=symbol_out,
dir_out=dir_out,
state_out=state_out,
)
yield new_tm_enumThe outline of the procedure is clear: at the branch point, determine the available instructions based on the combination of already-used states and colors and maximum possible states and colors, then create extensions from them. There are three easy ways to improve this.
At the start of the branch, the program stops to check how many and which instructions it has used so far. But the parameters of the child program can be derived from the parameters of the parent program plus the extension instruction, so really the program should already know this information about itself. If each node keeps track of its parameter information and passes it on to its extensions, the parameter recalculation can be skipped entirely.
Given the available parameters, the available instructions are generated on the fly every time. But in practice the maximum available parameters are never all that large. So it is much faster to generate a table of all possible available instructions just once up front. Then the branching program can hold a reference to that table and index in with available parameters as needed. This will look something like:
avail_instrs: list[Instruction] = self.table[avail_states][avail_colors]Then at branch-time, obtaining available instructions is just a fetch operation, no generation required.
With the instruction table approach, extension creation looks like this:
for instr in avail_instrs:
new_tm_enum = copy.deepcopy(self)
new_tm_enum.set_trans(instr) # or whatever
yield new_tm_enumWe ran our program until it reached an undefined instruction, and now we are at the branch point, and we create one extended program for each available instruction. Well, what happens to the program object we were just running? Currently it gets thrown in the trash. But it is perfectly good and can continue to be used. And since the instructions are all there together, it is easy to accomplish this with some list manipulation:
*rest_instrs, last_instr = avail_instrs
for instr in rest_instrs:
new_tm_enum = copy.deepcopy(self)
new_tm_enum.set_trans(instr)
yield new_tm_enum
self.set_trans(last_instr)
yield selfThis saves one deepcopy call per branch and also reduces the amount of garbage that must be collected.

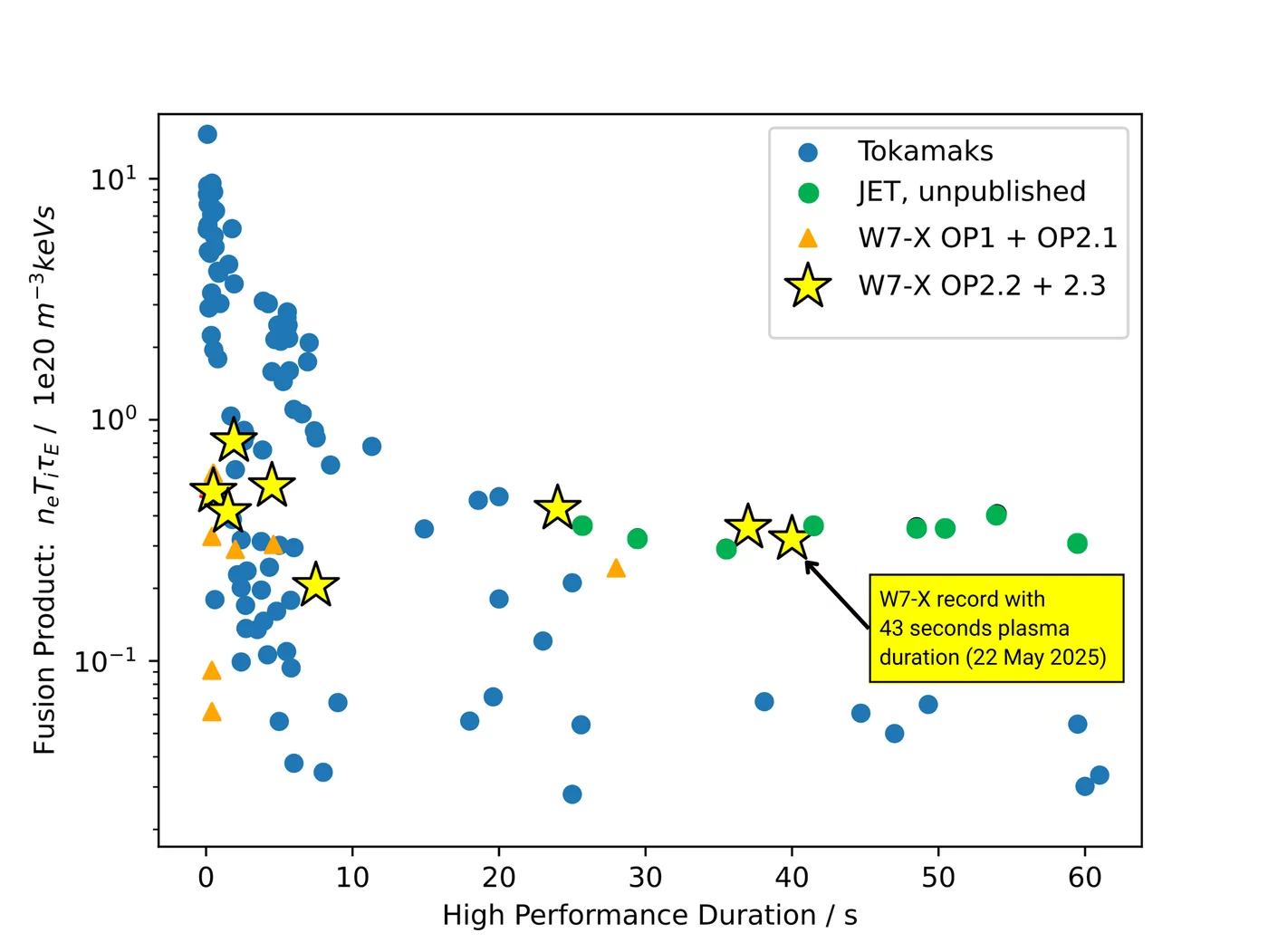
In nuclear fusion, the triple product – also known as the Lawson criterion – defines the point at which a nuclear fusion reaction produces more power than is needed to sustain the fusion reaction. Recently the German Wendelstein 7-X stellarator managed to hit new records here during its most recent OP 2.3 experimental campaign, courtesy of a frozen hydrogen pellet injector developed by the US Department of Energy’s Oak Ridge National Laboratory. With this injector the stellarator was able to sustain plasma for over 43 seconds as microwaves heated the freshly injected pellets.
Although the W7-X team was informed later that the recently decommissioned UK-based JET tokamak had achieved a similar triple product during its last – so far unpublished – runs, it’s of note that the JET tokamak had triple the plasma volume. Having a larger plasma volume makes such an achievement significantly easier due to inherently less heat loss, which arguably makes the W7-X achievement more noteworthy.
The triple product is also just one of the many ways to measure progress in commercial nuclear fusion, with fusion reactors dealing with considerations like low- and high-confinement mode, plasma instabilities like ELMs and the Greenwald Density Limit, as we previously covered. Here stellarators also seem to have a leg up on tokamaks, with the proposed SQuID stellarator design conceivably leap-frogging the latter based on all the lessons learned from W7-X.
Top image: Inside the vacuum vessel of Wendelstein 7-X. (Credit: Jan Hosan, MPI for Plasma Physics)
FurMark 2.9.0, the popular graphics card stress test and benchmarking tool, is available for Windows and Linux with bug fixes and improvements.
The post FurMark 2.9 GPU Stress Test and Graphics Benchmark first appeared on Geeks3D.
USB-C has enabled a lot of great things, most notably removing the no less than three attempts to plug in the cable correctly, but gone are the days of just 5V over those lines. [Meticulous Technologies] sent in their project to help easily identify what voltage your USB-C line is running at, the USB VSense.
The USB VSense is an inline board that has USB-C connectors on either end, and supporting up to 240W you don’t have to worry about it throttling your device. One of the coolest design aspects of this board is that it uses stacked PCB construction as the enclosure, the display, and the PCB doing all the sensing and displaying. And for sensing this small device has a good number of cool tricks, it will sense all the eight common USB-C voltages, but it will also measure and alert you to variations of the voltage outside the normal range by blinking the various colored LEDs in specific patterns. For instance should you have it plugged into a line that’s sitting over 48V the VSense white 48V LED will be rapidly blinking, warning you that something in your setup has gone horribly wrong.
Having dedicated uniquely colored LEDs for each common level allows you to at a glance know what the voltage is at without the need to read anything. With a max current draw of less than 6mA you won’t feel bad about using it on a USB battery pack for many applications.
The USB VSense has completed a small production run and has stated their intention to open source their design as soon as possible after their Crowd Supply campaign. We’ve featured other USB-C PD projects and no doubt we’ll be seeing more as this standard continues to gain traction with more and more devices relying on it for their DC power.
Anthony Salter has been working steadily on his 3D remake of the Ultima 7 engine over the last little while, and his most recent modifications to it have been focused on memory optimization and the implementation of 8-way 3D sprites.
Summary of last night's stream:
— Anthony Salter (@ViridianGames) June 30, 2025
* To reduce the memory footprint I completely changed how cuboids are draw in the engine. The good news is that they look more coherent and take up much less RAM. The bad news is that the format changed and there are some drawing issues that…
8-way sprites, if you weren’t familiar with the concept, are 3D-rendered object sprites that have eight distinct viewing angles for each animation frame. The good Mr. Salter gives a keen example in these two X posts:
Here's the sprite sheet I'm using; it's from my previous game Planitia: pic.twitter.com/4GeshcI2nv
— Anthony Salter (@ViridianGames) July 5, 2025
Ultima VII Revisited 8-way sprite test: pic.twitter.com/fg6eafxBdX
— Anthony Salter (@ViridianGames) July 5, 2025
And when applied to Ultima 7-derived sprites, the results are pretty aesthetically pleasing (clipping notwithstanding):
Dinnertime! pic.twitter.com/5hUmvK9GMk
— Anthony Salter (@ViridianGames) July 8, 2025
As always, you can follow Anthony on X for up-to-the-moment updates about Ultima VII: Revisited, and you can find downloads of the engine in its current state at the project’s website.
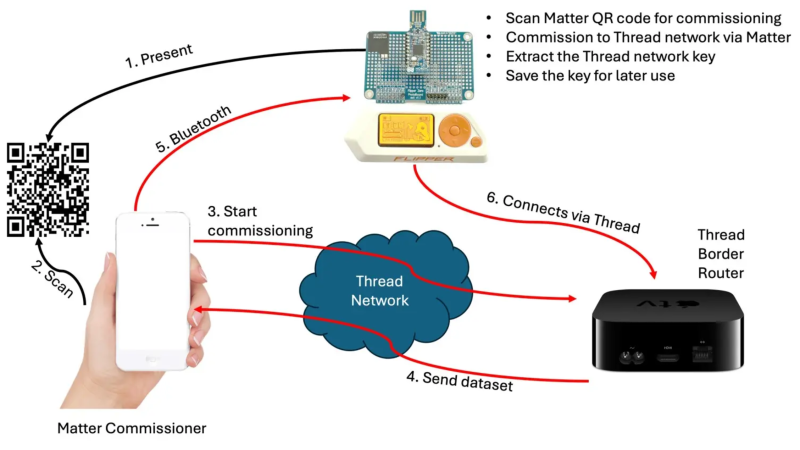
Gone are the days when all smart devices were required an internet uplink. The WiFi-enabled IoT fad, while still upon us (no, my coffee scale doesn’t need to be on the network, dammit!) has begun to give way to low-power protocols actually designed for this kind of communication, such as ZigBee, and more recently, Thread. The downside of these new systems, however, is that they can be a bit more difficult in which to dabble. If you want to see just why your WiFi-enabled toaster uploads 100 MB of data per day to some server, you can capture some network traffic on your laptop without any specialized hardware. These low-power protocols can feel a bit more opaque, but that’s easily remedied with a dev board. For a couple of dollars, you can buy Thread radio that, with some additional hacking, acts as a portal between this previously-arcane protocol and your laptop — or, as [András Tevesz] has shown us, your Flipper Zero.
He’s published a wonderful three-part guide detailing how to mod one such $10 radio to communicate with the Flipper via its GPIO pins, set up a toolchain, build the firmware, and start experimenting. The guide even gets into the nitty-gritty of how data is handled transmitted and investigates potential attack vectors (less worrying for your Thread-enabled light bulb, very worrying for your smart door lock). This project is a fantastic way to prototype new sensors, build complicated systems using the Flipper as a bridge, or even just gain some insight into how the devices in your smart home operate.
In 2025, it’s easier than ever to get started with home automation — whether you cook up a solution yourself, or opt for a stable, off-the-shelf (but still hackable) solution like HomeAssistant (or even Minecraft?). Regardless of the path you choose, you’ll likely wind up with devices on the Thread network that you now have the tools to hack.
I wrote here in 2023 about some of the many issues surrounding the development of antibody-drug conjugates, which is a field that’s come back around several times over the years. We are nowhere near finished working out its complexities, and its promise (of extremely selective and high-effective-potency dosing) remains great enough to justify a lot of work and expense.
I mentioned at the end of that post that a lot of new ideas were in the works, and one of those is moving into the clinic as we speak: the “dual-payload” ADCs. This is where you take an optimized antibody to (say) a particular tumor cell antigen, one chosen for its specificity over normal tissue, and attach two different sorts of “warhead” to it simultaneously. So instead of delivering just a topoisomerase inhibitor, you could deliver one of those at the same time as (say) a tubulin inhibitor, an RNA polymerase inhibitor, an ATR inhibitor, or what have you. Here’s a recent review of concepts in the area, and here’s another.
That process may not sound simple, and it’s even less simple than it sounds. As that last link notes, you have several factors to optimize. First, you have to make sure that your two mechanisms can reach their full potential against the tumor cells without interfering with each others’ modes of action. You also have to see how efficiently both of them are being delivered to those cells. That will probably involve some linker optimization, which is an issue that I spoke about recently here. (That lysosomal escape issue discussed there is a big part of getting ADCs to work in general). Optimizing one linker is not a lot of fun, so optimizing two simultaneously is pretty much guaranteed to be less so. You also have a number of choices to make about where those linkers are attached to the antibody structure and how you’d like to see them cleaved once inside the cell. And of course you have to end up with a process that can be reliably reproduced industrially, as always.
The rationale behind dual-payload dosing is easy to understand, though: resistance. Tumor cells are constantly dividing and throwing off mutations (much like bacteria do), and anticancer drug resistance is thus a similar problem to antibiotic resistance. You are trying to kill this easily mutated population, and all it takes is one successful pathway out of your drug’s mechanism to make all for naught. Oh, you’ll see improvement for a while as the susceptible population of cells is killed off. But then you’ve just given the mutant survivors an open field to expand in, in as clear a case of selection pressure as you could ever not wish to see. If you’re hitting them with two mechanisms at once, though, then the cells have to roll for a much lower-probability double mutation that lets them escape both simultaneously. You could increase the odds of those considerably by dosing first with one agent, then with another when that one fails, but both at once is a much bigger challenge.
The hope is that the tumors won’t be up to it. As you can see from the Nature overview linked in the second paragraph, a whole list of such agents is lining up to go into patients (even including some triple-payload ideas, which is sort of a whole chemotherapy cocktail carried on a single antibody). It’s basically impossible to tell which of these ideas are going to work in the clinic, so I’m glad to see so many variations. There are different mechanistic targets, different modes and rates of release, all sorts of things. We should learn quite a bit about tumor response to these ideas, which could lead to an even better second generation.
But a big question - as with traditional chemotherapy cocktails - is whether you can get greater-than-additive (that is, synergistic) effects. There are a lot of claims for this sort of thing, particularly in immuno-oncology when combined with more classic methods, but proving that in humans is quite difficult. If you’re ever going to see it, you’d think that delivering the different agents directly into the target cells simultaneously would be the way to make it happen. Let’s hope.
Some months ago, my colleague Madeeha Javed and I wrote a tool to convert QEMU disk images into qcow2, writing the result directly to stdout.
This tool is called qcow2-to-stdout.py and can be used for example to create a new image and pipe it through gzip and/or send it directly over the network without having to write it to disk first.
This program is included in the QEMU repository: https://github.com/qemu/qemu/blob/master/scripts/qcow2-to-stdout.py
If you simply want to use it then all you need to do is have a look at these examples:
$ qcow2-to-stdout.py source.raw > dest.qcow2$ qcow2-to-stdout.py -f dmg source.dmg | gzip > dest.qcow2.gz
If you’re interested in the technical details, read on.
QEMU uses disk images to store the contents of the VM’s hard drive. Images are often in qcow2, QEMU’s native format (although a variety of other formats and protocols are also supported).
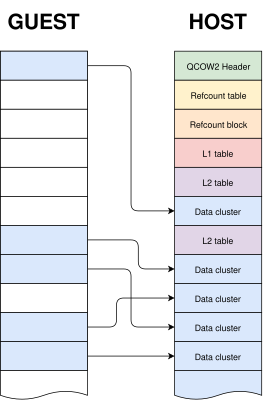
I have written in detail about the qcow2 format in the past (for example, here and here), but the general idea is very easy to understand: the virtual drive is divided into clusters of a certain size (64 KB by default), and only the clusters containing non-zero data need to be physically present in the qcow2 image. So what we have is essentially a collection of data clusters and a set of tables that map guest clusters (what the VM sees) to host clusters (what the qcow2 file actually stores).
qemu-img is a powerful and versatile tool that can be used to create, modify and convert disk images. It has many different options, but one question that sometimes arises is whether it can use stdin or stdout instead of regular files when converting images.
The short answer is that this is not possible in general. qemu-img convert works by checking the (virtual) size of the source image, creating a destination image of that same size and finally copying all the data from start to finish.
Reading a qcow2 image from stdin doesn’t work because data and metadata blocks can come in any arbitrary order, so it’s perfectly possible that the information that we need in order to start writing the destination image is at the end of the input data¹.
Writing a qcow2 image to stdout doesn’t work either because we need to know in advance the complete list of clusters from the source image that contain non-zero data (this is essential because it affects the destination file’s metadata). However, if we do have that information then writing a new image directly to stdout is technically possible.
The bad news is that qemu-img won’t help us here: it uses the same I/O code as the rest of QEMU. This generic approach makes total sense because it’s simple, versatile and is valid for any kind of source and destination image that QEMU supports. However, it needs random access to both images.
If we want to write a qcow2 file directly to stdout we need new code written specifically for this purpose, and since it cannot reuse the logic present in the QEMU code this was written as a separate tool (a Python script).
The process itself goes like this:
Images created with this program always have the same layout: header, refcount tables and blocks, L1 and L2 tables, and finally all data clusters.
One problem here is that, while QEMU can read many different image formats, qcow2-to-stdout.py is an independent tool that does not share any of the code and therefore can only read raw files. The solution here is to use qemu-storage-daemon. This program is part of QEMU and it can use FUSE to export any file that QEMU can read as a raw file. The usage of qemu-storage-daemon is handled automatically and the user only needs to specify the format of the source file:
$ qcow2-to-stdout.py -f dmg source.dmg > dest.qcow2
qcow2-to-stdout.py can only create basic qcow2 files and does not support features like compression or encryption. However, a few parameters can be adjusted, like the cluster size (-c), the width of the reference count entries (-r) and whether the new image is created with the input as an external data file (-d and -R).
And this is all, I hope that you find this tool useful and this post informative. Enjoy!
This work has been developed by Igalia and sponsored by Outscale, a Dassault Systèmes brand.

¹ This problem would not happen if the input data was in raw format but in this case we would not know the size in advance.
The Supreme Court’s recent decision in Free Speech Coalition v. Paxton did not end the legal debate over age-verification mandates for websites. Instead, it’s a limited decision: the court’s legal reasoning only applies to age restrictions on sexual materials that minors do not have a legal right to access. Although the ruling reverses decades of First Amendment protections for adults to access lawful speech online, the decision does not allow states or the federal government to impose broader age-verification mandates on social media, general audience websites, or app stores.
At EFF, we continue to fight age-verification mandates in the many other contexts in which we see them throughout the country and the world. These “age gates” remain a threat to the free speech and privacy rights of both adults and minors.
Importantly, the Supreme Court’s decision does not approve of age gates when they are imposed on speech that is legal for minors and adults.
The court’s legal reasoning in Free Speech Coalition v. Paxton depends in all relevant parts on the Texas law only blocking minors’ access to speech to which they had no First Amendment right to access in the first place—what has been known since 1968 as “harmful to minors” sexual material. Although laws that limit access to certain subject matters are typically required to survive “strict scrutiny,” the Texas law was subject instead to the less demanding “intermediate scrutiny” only because the law was denying minors access to this speech that was unprotected for them. The Court acknowledged that having to prove age would create an obstacle for adults to access speech that is protected for them. But this obstacle was merely “incidental” to the lawful restriction on minors’ access. And “incidental” restrictions on protected speech need only survive intermediate scrutiny.
To be clear, we do not agree with this result, and vigorously fought against it. The Court wrongly downplayed the very real and significant burdens that age verification places on adults. And we disagree with numerous other doctrinal aspects of the Court’s decision. The court had previously recognized that age-verification schemes significantly burden adult’s First Amendment rights and had protected adults’ constitutional rights. So Paxton is a significant loss of internet users’ free speech rights and a marked retreat from the court’s protections for online speech.
The decision does not allow states or the federal government to impose broader age-verification mandates
But the decision is limited to the specific context in which the law seeks to restrict access to sexual materials. The Texas law avoided strict scrutiny only because it directly targeted speech that is unprotected as to minors. You can see this throughout the opinion:
There is only sentence in Free Speech Coalition v. Paxton addressing the restriction of First Amendment rights that is not cabined by the language of unprotected harmful to minors speech. The Court wrote: “And, the statute does not ban adults from accessing this material; it simply requires them to verify their age before accessing it on a covered website.” But that sentence was entirely surrounded by and necessarily referred to the limited situation of a law burdening only access to harmful to minors sexual speech.
We and the others fighting online age restrictions still have our work cut out for us. The momentum to widely adopt and normalize online age restrictions is strong. But Free Speech Coalition v. Paxton did not approve of age gates when they are imposed on speech that adults and minors have a legal right to access. And EFF will continue to fight for all internet users’ rights to speak and receive information online.
Doom fans, here is something really special for you today. Lee Hardcastle has shared this incredible claymation tribute to all the Doom games. This is easily the best thing you’ll see today. So, waste no time and watch it. This fan video shows all the Doom games, from the classic ones to Doom: The Dark … Continue reading This claymation tribute to all Doom games is one of the best things you’ll see today
The post This claymation tribute to all Doom games is one of the best things you’ll see today appeared first on DSOGaming.

We’ve just begun to receive entries to the One Hertz Challenge, but we already have an entry by [Mike Coats] that explicitly demands to be awarded last place: the Metronalmost, a metronome that will never, ever, tick at One Hertz.
Unlike a real metronome that has to rely on worldly imperfections to potentially vary the lengths of its ticks, the metronoalmost leaves nothing to chance: it’s driven by a common hobby servo wired directly to a NodeMCU ESP-12E, carefully programmed so that the sweep will never take exactly one second.

The mathematics required to aggressively subvert our contest are actually kind of interesting: start with a gaussian distribution, such as you can expect from a random number generator. Then subtract a second, narrower distribution centered on one (the value we, the judges want to see) to create a notch function. This disribution can be flipped into a mapping function, but rather than compute this on the MCU, it looks like [Mike] has written a lookup table to map values from his random number generator. The output values range from 0.5 to 1.5, but never, ever, ever 1.0.
The whole thing goes into a cardboard box, because you can’t hit last place with a masterfully-crafted enclosure. On the other hand, he did print out and glue on some fake woodgrain that looks as good as some 1970s objects we’ve owned, so there might be room for (un)improvement there.
While we can’t think of a better subversion of this contest’s goals, there’s still time to come up with something that misses the point even more dramatically if you want to compete with [Mike] for last place: the contest deadline is 9:00 AM Pacific time on August 19th.
Or, you know, if you wanted to actually try and win. Whatever ticks your tock.


« Normal science, the activity in which most scientists inevitably spend most all their time, is predicated on the assumption that the scientific community knows what the world is like. Normal science often suppresses fundamental novelties because they are necessarily subversive of its basic commitments. As a puzzle-solving activity, normal science does not aim at novelties of fact or theory and, when successful, finds none. » Thomas Kuhn
The linear model of innovation is almost entirely backward. This model describes progress like so: University professors and their students develop the new ideas, these ideas are then taken up by industry which deploys them.
You can come up with stories that are supportive of this model… But on the ground, we are still fighting to get UML and the waterfall model off the curriculum. Major universities still forbid the use of LLMs in software courses (as if they could).
Universities are almost constantly behind. Not only are they behind, they often promote old, broken ideas. Schools still teach about the ‘Semantic Web’ in 2025.
Don’t get me wrong. The linear model can work, sometimes. It obviously can. But there are preconditions, and these preconditions are rarely met.
Part of the issue is ‘peer review’ which has grown to cover everything. ‘Peer review’ means ‘do whatever your peers are doing and you will be fine’. It is fundamentally reactionary.
Innovations still emerge from universities, but through people who are rebels. They either survive the pressure of peer review, or are just wired differently.
Regular professors are mostly conservative forces. To be clear, I do not mean ‘right wing’. I mean that they are anchored in old ideas and they resist new ones.
Want to see innovation on campus ? Look for the rebels.

You would think detecting lightning would be easy. Each lightning bolt has a staggering amount of power, and, clearly, you can hear the results on any radio. But it is possible to optimize a simple receiver circuit to specifically pick up lightning. That’s exactly what [Wenzeltech] shows in a page with several types of lightning detectors complete with photos and schematics.
Just as with a regular radio, there are multiple ways to get the desired result. The first circuits use transistors. Later versions move on to op amps and even have “storm intensity” meters. The final project uses an ion chamber from a smoke detector. It has the benefit of being very simple, but you know, also slightly radioactive.
You might think you could detect lightning by simply looking out the window. While that’s true, you can, in theory, detect events from far away and also record them easily using any data acquisition system on a PC, scope, or even logic analyzer.
Why? We are sure there’s a good reason, but we’ve never needed one before. These designs look practical and fun to build, and that’s good enough for us.
You can spruce up the output easily. You can also get it all these days, of course, on a chip.

After the fire and fury of liftoff, when a spacecraft is sailing silently through space, you could be forgiven for thinking the hard part of the mission is over. After all, riding what’s essentially a domesticated explosion up and out of Earth’s gravity well very nearly pushes physics and current material science to the breaking point.
![]() But in reality, getting into space is just the first on a long list of nearly impossible things that need to go right for a successful mission. While scientific experiments performed aboard the International Space Station and other crewed vehicles have the benefit of human supervision, the vast majority of satellites, probes, and rovers must be able to operate in total isolation. With nobody nearby to flick the power switch off and on again, such craft need to be designed with multiple layers of redundant systems and safe modes if they’re to have any hope of surviving even the most mundane system failure.
But in reality, getting into space is just the first on a long list of nearly impossible things that need to go right for a successful mission. While scientific experiments performed aboard the International Space Station and other crewed vehicles have the benefit of human supervision, the vast majority of satellites, probes, and rovers must be able to operate in total isolation. With nobody nearby to flick the power switch off and on again, such craft need to be designed with multiple layers of redundant systems and safe modes if they’re to have any hope of surviving even the most mundane system failure.
That said, nobody can predict the future. Despite the best efforts of everyone involved, there will always be edge cases or abnormal scenarios that don’t get accounted for. With proper planning and a pinch of luck, the majority of missions are able to skirt these scenarios and complete their missions without serious incident.
Unfortunately, Lunar Trailblazer isn’t one of those missions. Things started well enough — the February 26th launch of the SpaceX Falcon 9 went perfectly, and the rocket’s second stage gave the vehicle the push it needed to reach the Moon. The small 210 kg (460 lb) lunar probe then separated from the booster and transmitted an initial status message that was received by the Caltech mission controllers in Pasadena, California which indicated it was free-flying and powering up its systems.
But since then, nothing has gone to plan.
According to NASA’s blog for Lunar Trailblazer, Caltech first heard from the spacecraft about 12 minutes after it separated from the second stage of the Falcon 9. At this point the spacecraft was at an altitude of approximately 1,800 kilometers (1118 miles) and had been accelerated by the booster to a velocity of more than 33,000 km/h (20,500 mph). The craft was now committed to a course that would take it away from Earth, although further course correction maneuvers would be required to put it into its intended orbit around the Moon.
The team on the ground started to receive the expected engineering telemetry data from the vehicle, but noted that there were some signals that indicated intermittent issues with the power supply. Around ten hours later, the Lunar Trailblazer spacecraft went completely silent for a short period of time before reactivating its transmitter.
At this point, it was obvious that something was wrong, and ground controllers started requesting more diagnostic information from the spacecraft to try and determine what was going on. But communication with the craft remained unreliable, at best. Even with access to NASA’s powerful Deep Space Network, the controllers could not maintain consistent contact with the vehicle.
On March 2nd, ground-based radars were able to get a lock on Lunar Trailblazer. The good news was that the radar data confirmed that the spacecraft was still intact. The bad news is that the team at Caltech now had a pretty good idea as to why they were only getting sporadic communications from the vehicle — it was spinning in space.
This might not seem like a problem at first, indeed some spacecraft use a slight spin to help keep them stabilized. But in the case of Lunar Trailblazer, it meant the vehicle’s solar arrays were not properly orientated in relation to the sun. The occasional glimpses of sunlight the panels would get as the craft tumbled explained the sporadic nature of its transmissions, as sometimes it would collect just enough power to chirp out a signal before going dead again.
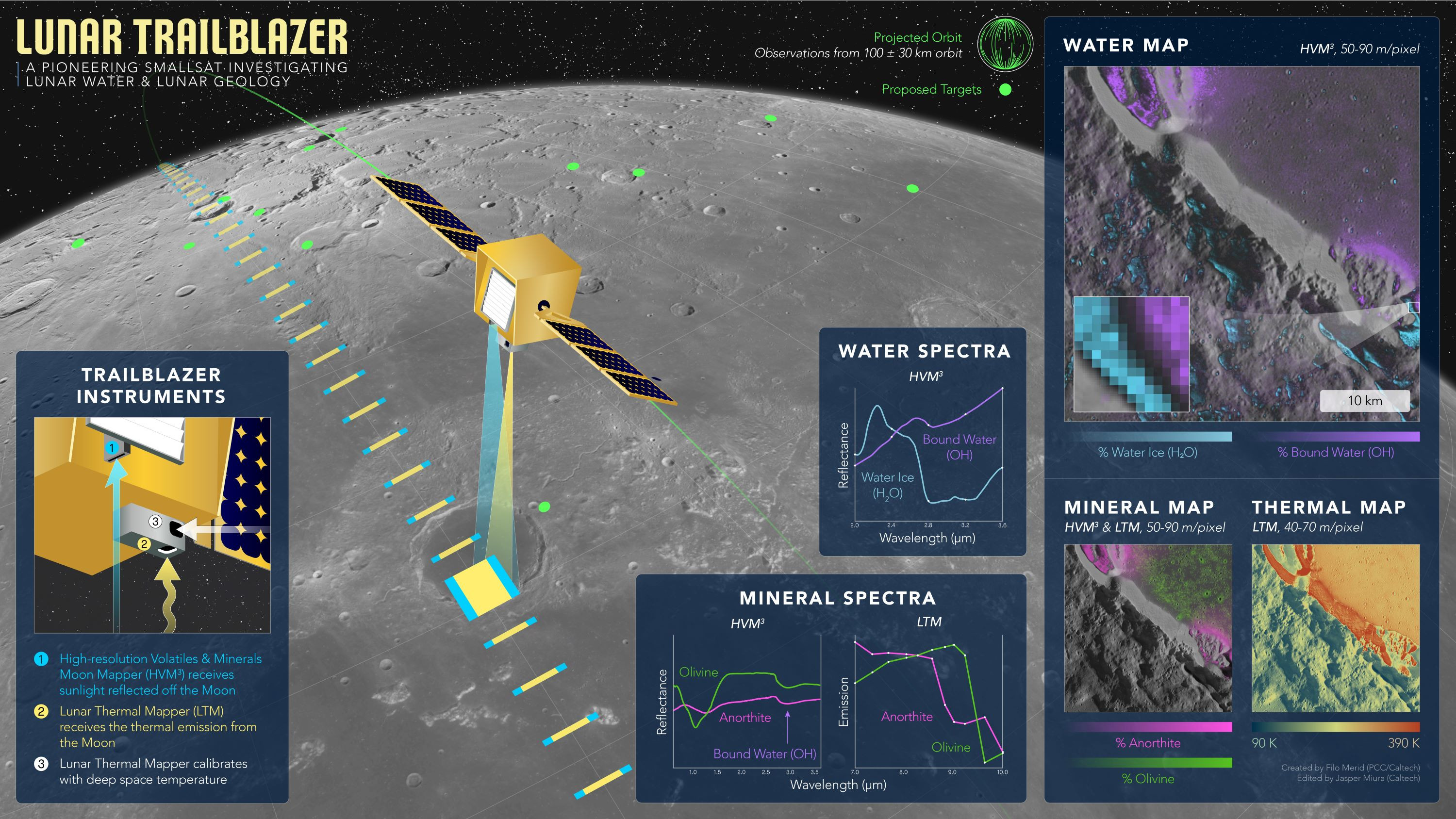
But there was a now a new dimension to the problem. By March 4th, the the spacecraft was supposed to have made the first of several trajectory correction maneuvers (TCMs) to refine its course towards the Moon. As those TCMs never happened, Lunar Trailblazer was now off-course, and getting farther away from its intended trajectory every day.
By now, ground controllers knew it was unlikely that Lunar Trailblazer would be able to complete all of the mission’s science goals. Even if they could reestablish communication, the vehicle wasn’t where it was supposed to be. While it was still theoretically possible to compute a new course and bring the vehicle into lunar orbit, it wouldn’t be the one that the mission’s parameters called for.
The mission was in a bad place, but the controllers at Caltech still had a few things going in their favor. For one, they knew exactly what was keeping them from communicating with the spacecraft. Thanks to the ongoing radar observations, they also had highly-accurate data on the velocity, position, and rotation rate of the craft. Essentially, they knew what all the variables were, they just needed to figure out the equation that would provide them with a solution.
Over the next couple of months, the data from the radar observations was fed into a computer model that allowed ground controllers to estimate how much sunlight would hit Lunar Trailblazer’s solar array at a given time. Engineers worked with a replica of the spacecraft’s hardware to better understand not only how it operated while in a low-power state, but how it would respond when it got a sudden jolt of power.
The goal was to find out exactly how long it would take for the spacecraft to come back to a workable state when the solar array was lit, and then use the model to find when the vehicle and the sun would align for long enough to make it happen.
It was originally believed that they only had until June for this celestial alignment to work in their favor, but refined data allowed NASA and Caltech to extend that timetable into the middle of July. With that revised deadline fast approaching, we’re eager to hear an update from the space agency about the fate of this particularly tenacious lunar probe.
Too often I've been accused of making you readers hungry with my steady parade of candy-coated misspellings and butchered bakery goods.
Well, NO MORE!
Or at least not for today.
Here, I'll ease you in slowly, in case you're mid coffee-sip:

This is your spleen...or possibly a giant tumor...on cupcakes.
Any questions?
I've been told there are no accidents in life; only learning experiences. If that's true, then we're all about to learn something very important:

Some bakers get sick if you feed them too many mini-marshmallows.
Also, we're not hungry. No, none of us. Now go away. Shoo.
Before you ask, this "cake" was being served at a buffet restaurant, and no, that's not mold:

It just looks like mold. Thereby saving the establishment literally dozens of dollars in their dessert budget, I'm sure. (Reminds me of the restaurant with candy sprinkles on their sushi rolls. Hey... do you think it's the same place?)

I'm not really sure what's happening in there, but it's a safe bet you're not getting your little plastic purse back.
The tag on this next one says, "Freshly made in store by our bakers."

And thank goodness for that! There's just nothing worse than stale vomit from some factory, am I right?
Also...are those...olives? (Deep breaths, Jen...deep...breaths...)
Baker by day, retirement-center barber by night?

EWWWWWWW.
Ok, I just made MYSELF gag. Urg. And no, I don't know what the "hair" is really. Let's just try not to think about it too hard, okay?

Hey, now, WHAT DID I JUST SAY?
Ah, well, don't worry. Someone'll just stick that on the clearance rack later.
You know, once it cools.
Thanks to Rob A., Emily F., Dani S., Andrea & Anne Marie, Mim & Vince, Lisa D., & Regina G. for the uplifting chucking experience. Who's hungry now, bee-yotches? HUH?
*****
For some reason this post is just calling out for butt-themed home decor, don't you agree?

*****
And from my other blog, Epbot:

Build A Rocket Boy has finally released the third update for the PC version of MindsEye. This patch is 11GB in size, and it most likely includes all the tweaks and fixes that were available in the console patch. So, the big question is: does this third patch bring any major performance improvements to the … Continue reading MindsEye PC Patch 3 is 11.6GB in size, available for download
The post MindsEye PC Patch 3 is 11.6GB in size, available for download appeared first on DSOGaming.
Need for Speed fans, here is something for you today. Modder alessandro893 has released Version 0.5 for his amazing RTX Remix Mod for Need for Speed: Underground. This mod adds real-time Path Tracing to this classic racing game. So, let’s see what this new version brings to the table. Version 0.5 has over 500 new … Continue reading Need for Speed: Underground RTX Remix Mod V0.5 Released
The post Need for Speed: Underground RTX Remix Mod V0.5 Released appeared first on DSOGaming.
If you’re headed for another planet, celestial markers can keep your spacecraft properly oriented. Mariner 4 used Canopus, a bright star in the constellation Carina, as an attitude reference, its star tracker camera locking onto the star after its Sun sensor had locked onto the Sun. This was the first time a star had been used to provide second axis stabilization, its brightness (second brightest star in the sky) and its position well off the ecliptic making it an ideal referent.
The stars are, of course, a navigation tool par excellence. Mariners of the sea-faring kind have used celestial navigation for millennia, and I vividly remember a night training flight in upstate New York when my instructor switched off our instrument panel by pulling a fuse and told me to find my way home. I was forcefully reminded how far we’ve come from the days when the night sky truly was a celestial map for travelers. Fortunately, a few bright cities along the way made dead reckoning an easy way to get home that night. But I told myself I would learn to do better at stellar navigation. I can still hear my exasperated instructor as he pointed out one celestial marker: “For God’s sake, see that bright star? Park it over your left wingtip!”
Celestial navigation of various kinds can be done aboard a spacecraft, and the use of pulsars will help future deep space probes navigate autonomously. Until then, our methods rely heavily on ground-based installations. Delta-Differential One-Way Ranging (Delta-DOR or ∆DOR) can measure the angular location of a target spacecraft relative to a reference direction, the latter being determined by radio waves from a source like a quasar, whose angular position is well known. Only the downlink signal from the spacecraft is used in a precision technique that has been employed successfully on such missions as China’s Chang’e, ESA’s Rosetta and NASA’s Mars Reconnaissance Orbiter.
The Deep Space Network and Delta-DOR can perform marvels in terms of the directional location of a spacecraft. But we’ve also just had a first in terms of autonomous navigation through the work of the New Horizons team. Without using radio tracking from Earth, the spacecraft has determined its distance and direction by examining images of star fields and the observed parallax effects. Wonderfully, the two stars that the team chose for this calculation were Wolf 359 and Proxima Centauri, two nearby red dwarfs of considerable interest.
The images in question were captured by New Horizons’ Long Range Reconnaissance Imager (LORRI) and studied in relation to background stars. These twp stars are almost 90 degrees apart in the sky, allowing team scientists to flag New Horizons’ location. The LORRI instrument offers limited angular resolution and is here being used well outside the parameters for which it was designed, but even so, this first demonstration of autonomous navigation didn’t do badly, finding a distance close to the actual distance of the spacecraft when the images were taken, and a direction on the sky accurate to a patch about the size of the full Moon as seen from Earth. This is the largest parallax baseline ever taken, extending for over four billion miles. Higher resolution imagers, as reported in this JHU/APL report, should be able to do much better.
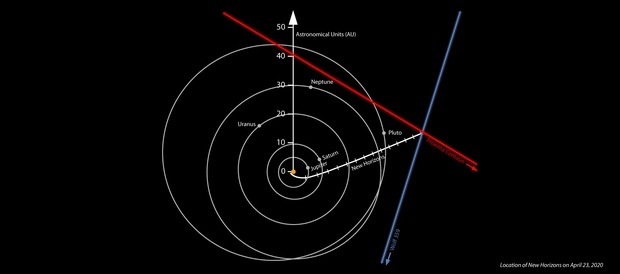
Image: Location of NASA’s New Horizons spacecraft on April 23, 2020, derived from the spacecraft’s own images of the Proxima Centauri and Wolf 359 star fields. The positions of Proxima Centauri and Wolf 359 are strongly displaced compared to distant stars from where they are seen on Earth. The position of Proxima Centauri seen from New Horizons means the spacecraft must be somewhere on the red line, while the observed position of Wolf 359 means that the spacecraft must be somewhere on the blue line – putting New Horizons approximately where the two lines appear to “intersect” (in the real three dimensions involved, the lines don’t actually intersect, but do pass close to each other). The white line marks the accurate Deep Space Network-tracked trajectory of New Horizons since its launch in 2006. The lines on the New Horizons trajectory denote years since launch. The orbits of Jupiter, Saturn, Uranus, Neptune and Pluto are shown. Distances are from the center of the solar system in astronomical units, where 1 AU is the average distance between the Sun and Earth. Credit: NASA/Johns Hopkins APL/SwRI/Matthew Wallace.
Brian May, known for his guitar skills with the band Queen as well as his knowledge of astrophysics, helped to produce the images below that show the comparison between these stars as seen from Earth and from New Horizons. A co-author of the paper on this work, May adds:
“It could be argued that in astro-stereoscopy — 3D images of astronomical objects – NASA’s New Horizons team already leads the field, having delivered astounding stereoscopic images of both Pluto and the remote Kuiper Belt object Arrokoth. But the latest New Horizons stereoscopic experiment breaks all records. These photographs of Proxima Centauri and Wolf 359 – stars that are well-known to amateur astronomers and science fiction aficionados alike — employ the largest distance between viewpoints ever achieved in 180 years of stereoscopy!”
Here are two animations showing the parallax involving each star, with Proxima Centauri being the first image. Note how the star ‘jumps’ against background stars as the view from Earth is replaced by the view from New Horizons.


Image: In 2020, the New Horizons science team obtained images of the star fields around the nearby stars Proxima Centauri (top) and Wolf 359 (bottom) simultaneously from New Horizons and Earth. More recent and sophisticated analyses of the exact positions of the two stars in these images allowed the team to deduce New Horizons’ three-dimensional position relative to nearby stars – accomplishing the first use of stars imaged directly from a spacecraft to provide its navigational fix, and the first demonstration of interstellar navigation by any spacecraft on an interstellar trajectory. Credit: JHU/APL.
This result from New Horizons marks the first time that optical stellar astrometry has been applied to the navigation of a spacecraft, but it’s clear that our hitherto Earth-based methods of navigation in space will have to give way to on-board methods as we venture still farther out of the Solar System. Thus far the use of X-ray pulsars has been demonstrated only in Earth orbit, but it will surely be among the techniques employed. These rudimentary observations are likewise proof-of-concept whose accuracy will need dramatic improvement.
The paper notes the next steps in using parallactic measurements for autonomous navigation:
Considerably better performance should be possible using the cameras presently deployed on other interplanetary spacecraft, or contemplated for future missions. Telescopes with apertures plausibly larger than LORRI’s, with diffraction-limited optics, delivering images to Nyquist-sampled detectors [a highly accurate digital signal processing method], mounted on platforms with matching finepointing control, should be able to provide astrometry with few milli-arcsecond accuracy. Extrapolating from LORRI, position vectors with accuracy of 0.01 au should be possible in the near future.
The paper on this work is Lauer et al., “A Demonstration of Interstellar Navigation Using New Horizons,” accepted at The Astronomical Journal and available as a preprint.

